Five tools. Each ends with a concrete recommendation.
Trackers show where you stand in AI answers. These tools show what to do next: which sources are missing, what prompts your customers type, what is asked under your brand.
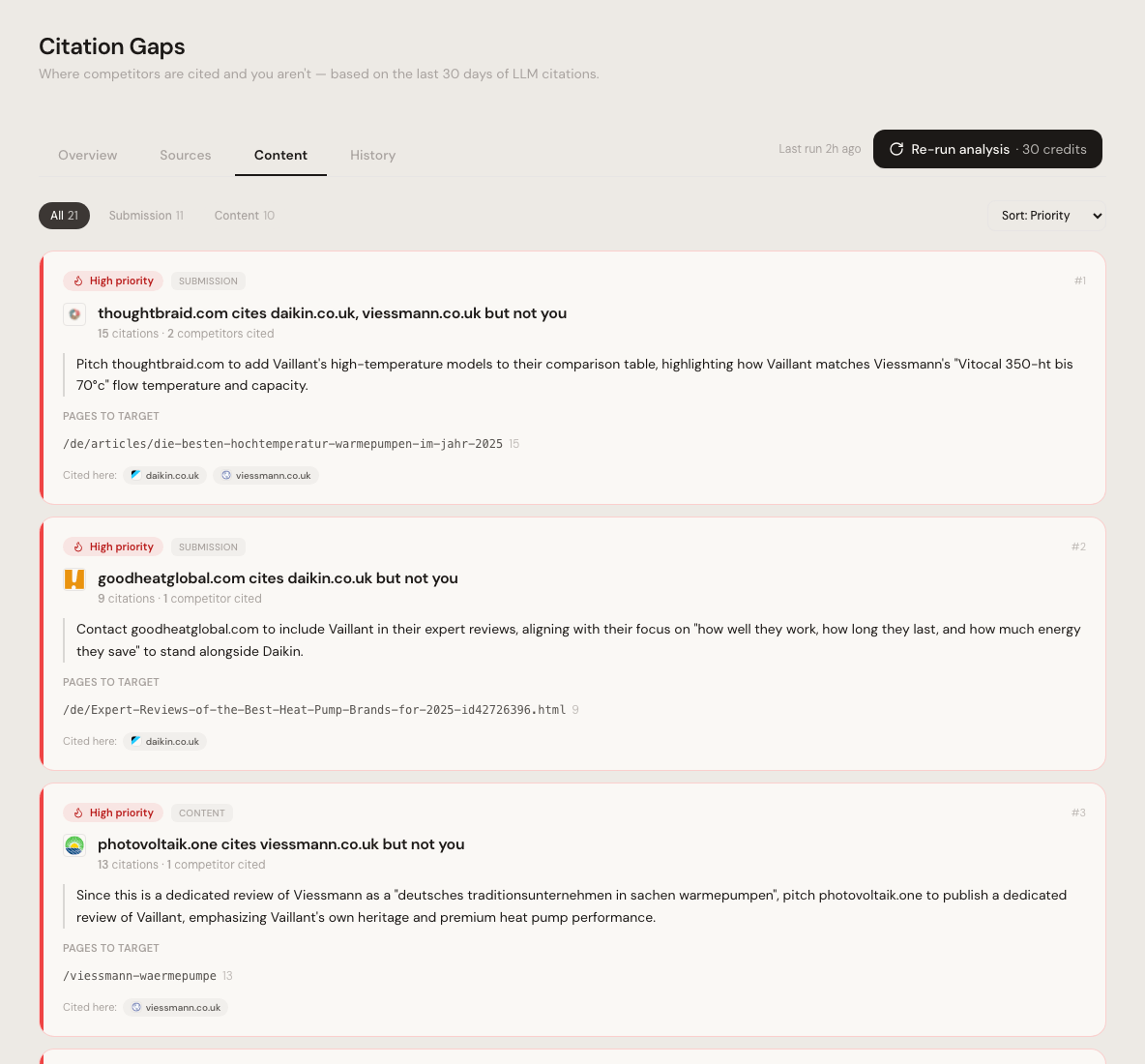
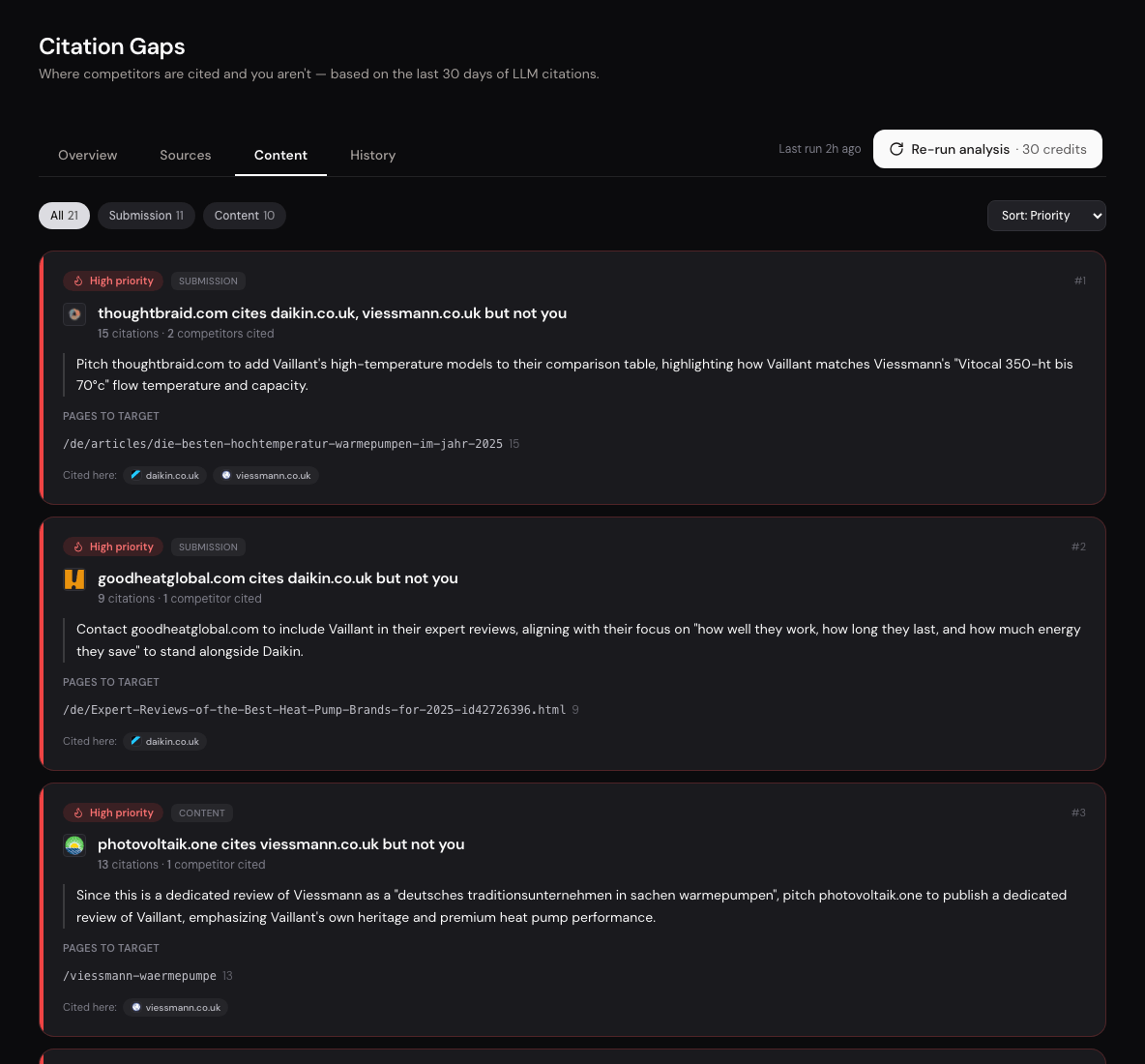
Citation Gaps. Source audit with recommendation.
Which sources recommend you today, which do not, and which three gaps to close first. Citation Gaps combines visibility data with source analysis and returns a prioritized list with reasoning per lever.
Details and sample outputPrompt Research. What your customers actually type.
Prompt Research finds the prompts common in your market, scores each with a confidence value, and imports them straight into tracking.
Suggests prompts in your topic you would not guess on your own, not generic volume.
Each suggestion carries a 1-to-5 confidence score so you see which prompts the model rates as relevant.
Filter by topic area and push selected prompts directly into your tracking set.
Fanout Queries. What LLMs ask under the hood.
A user types one sentence, and AI models generate multiple follow-up searches underneath. Fanout shows them, so you see what the models actually look up in the context of your brand.
The main prompt.
The sub-queries.
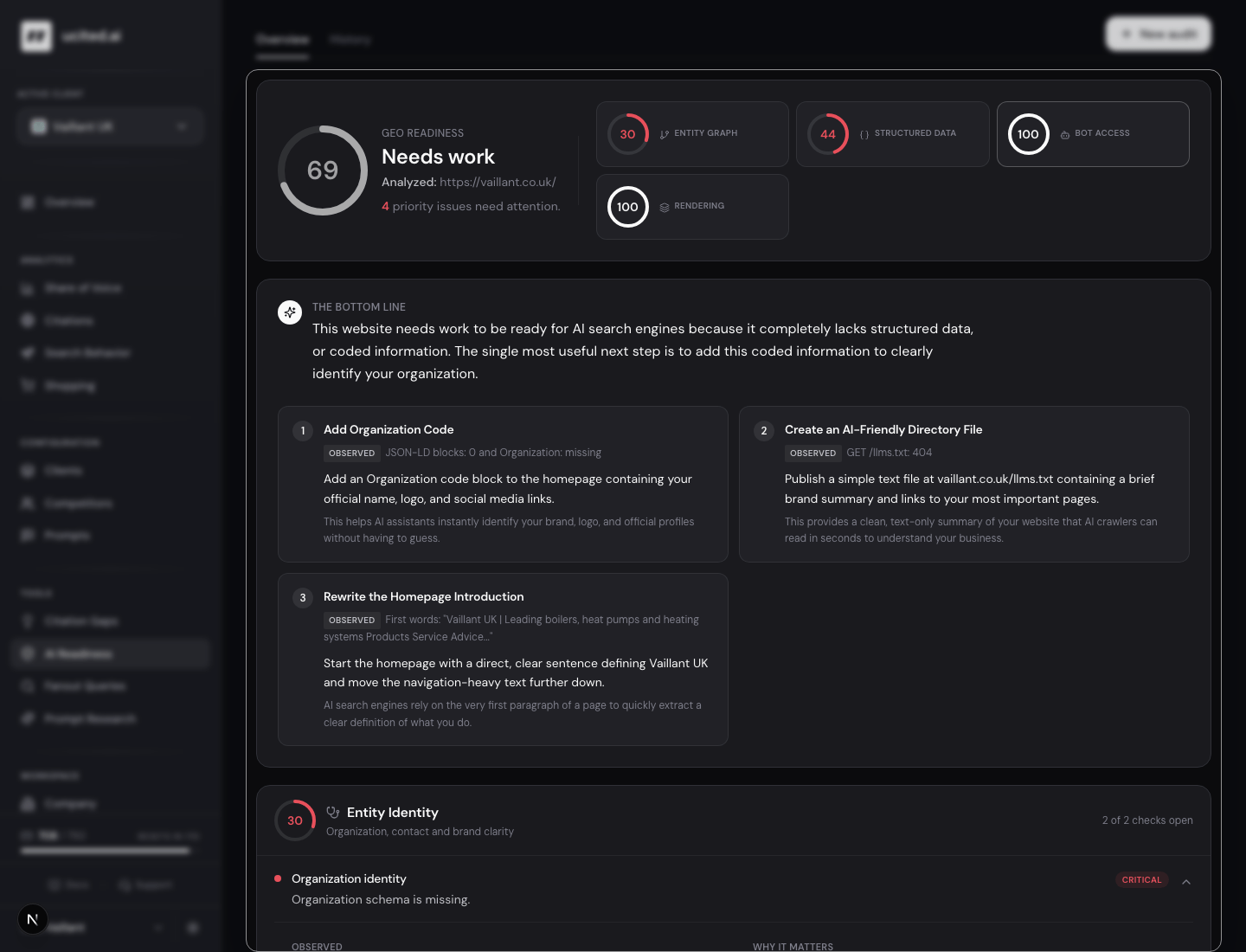
AI Readiness. One score, one actionable lever.
How well is a page prepared to be cited by AI models. AI Readiness returns a score per URL and a list of the three biggest levers, written so they can be executed.
Details and sample output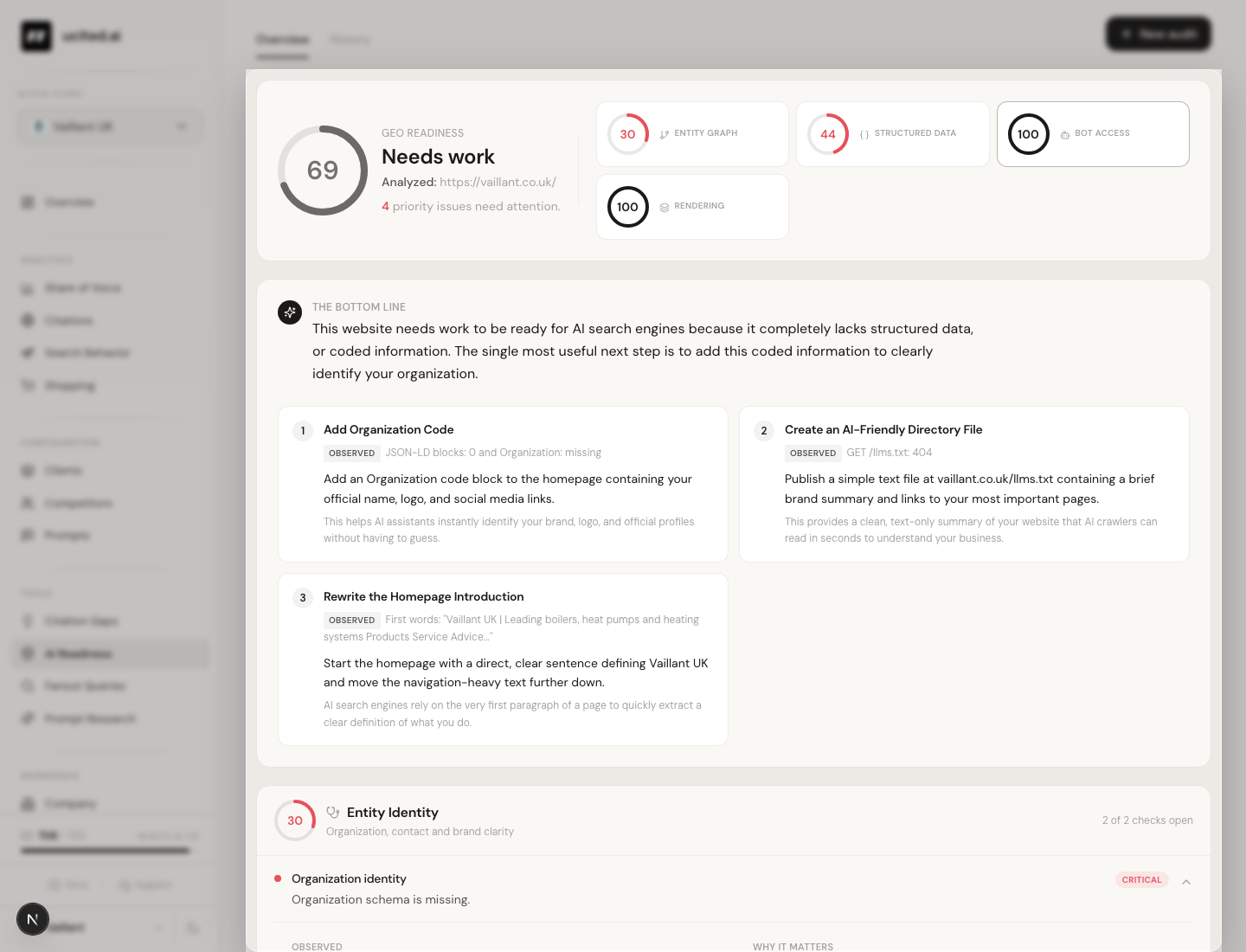


AI Files. Your website as files AI can read.
One run reads your content-heavy pages and generates the file bundle for AI systems: a curated llms.txt, the fuller llms-full.txt, and a fact-based facts page. Everything comes from your own pages — nothing is invented.
Not just numbers, but levers.
of Google searches with an AI summary still lead to a click on a website. Without one it is 15%.
Pew Research Center, 2025of B2B buyers use generative AI as a top information source in every phase of their buying journey.
Forrester, 2024Most dashboards show a score and leave interpretation to you. Across three brands per week that is a lot of work.
Every recommendation carries the data point and the logic that produced it. No black box.
Twenty possible levers are often as unusable as none. Three prioritized levers a week is what teams actually act on.