Fünf Werkzeuge. Jedes endet mit einer konkreten Empfehlung.
Tracker zeigen, wo du in KI-Antworten stehst. Diese Werkzeuge zeigen, was als nächstes zu tun ist: welche Quellen fehlen, welche Prompts deine Kunden tippen, was unter deiner Marke gefragt wird.
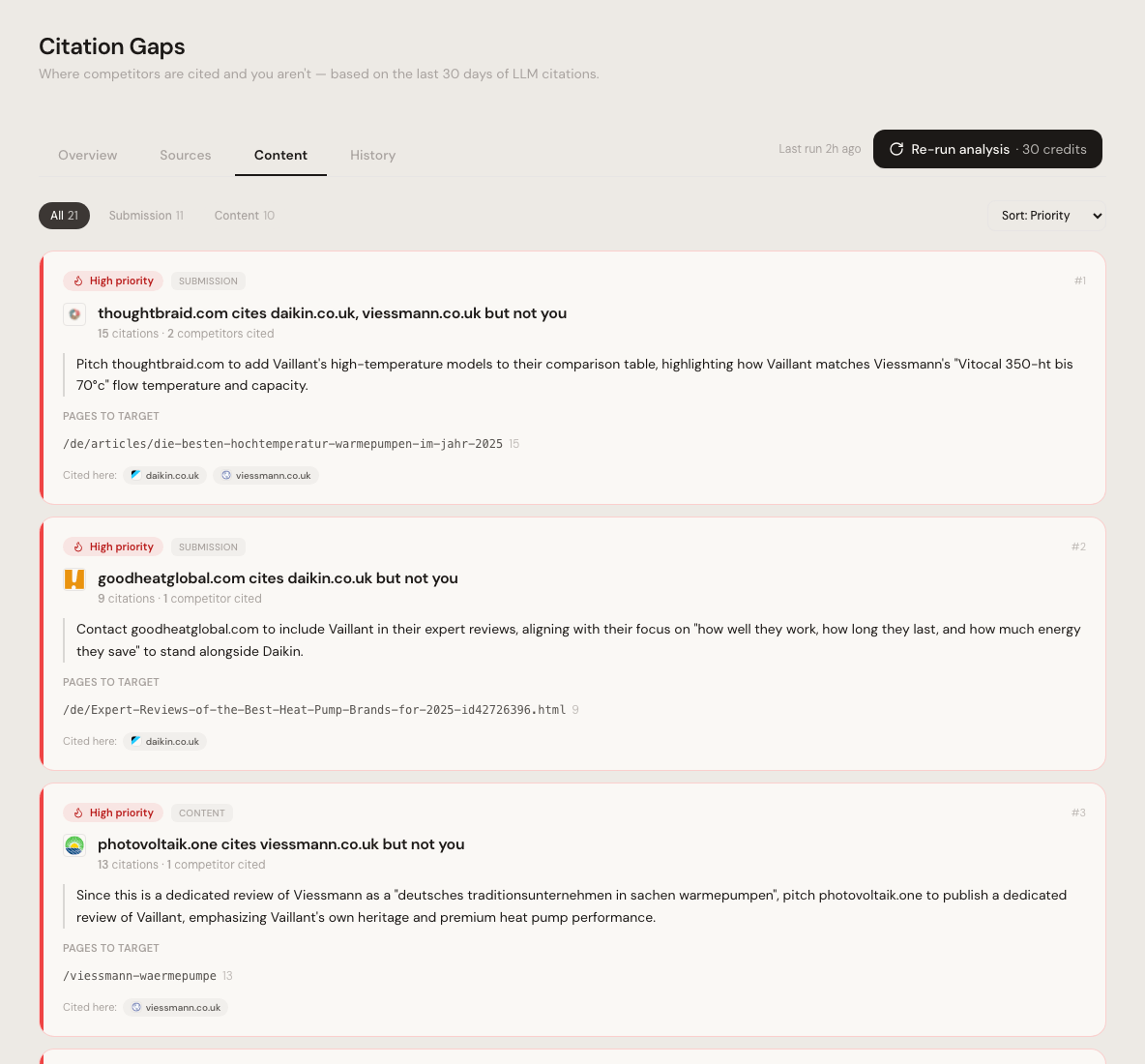
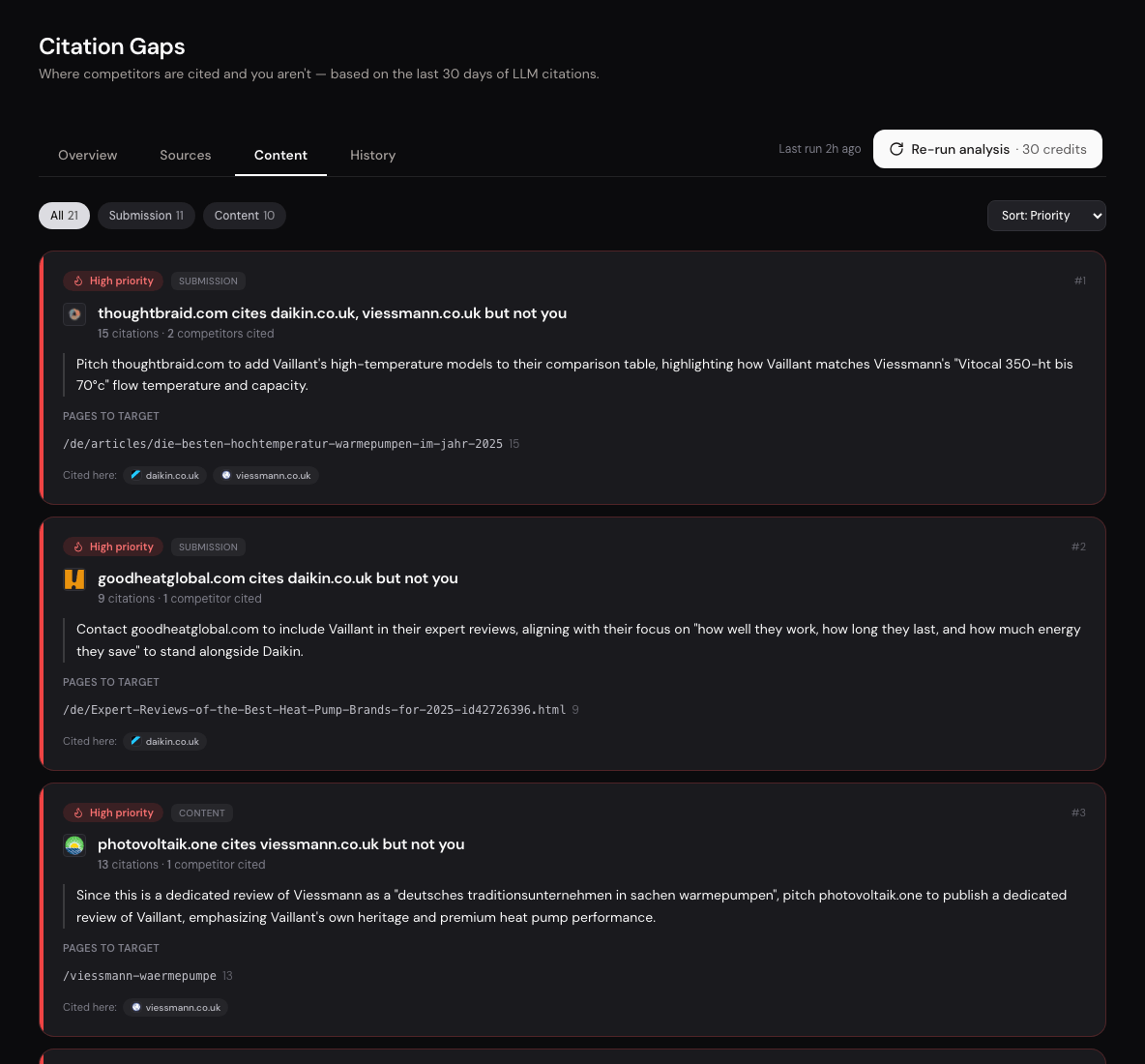
Citation Gaps. Quellen-Audit mit Empfehlung.
Welche Quellen empfehlen dich heute, welche nicht, und welche drei Lücken zuerst angehen. Citation Gaps kombiniert deine Sichtbarkeits-Daten mit einer Domain-Analyse und liefert eine priorisierte Liste mit Begründung pro Hebel.
Details und Beispiel-OutputPrompt Research. Was deine Kunden wirklich tippen.
Prompt Research findet die Prompts, die in deinem Markt häufig sind, bewertet jeden mit einem Konfidenz-Wert und übernimmt sie auf Wunsch direkt ins Tracking.
Schlägt Prompts aus deinem Thema vor, die du selbst nicht erraten würdest, statt generischem Volumen.
Jeder Vorschlag bekommt einen Konfidenz-Wert (1–5) — du siehst sofort, welche Prompts das Modell für relevant hält.
Filtere nach Themen-Bereich und übernimm gefundene Prompts direkt in dein Tracking-Set.
Fanout Queries. Was LLMs intern nachfragen.
Tippt ein Nutzer einen einzigen Satz, generieren KI-Modelle dahinter mehrere Folge-Suchen. Fanout zeigt sie, sodass du siehst, wonach die Modelle im Kontext deiner Marke wirklich suchen.
Den Hauptprompt.
Die Sub-Queries.
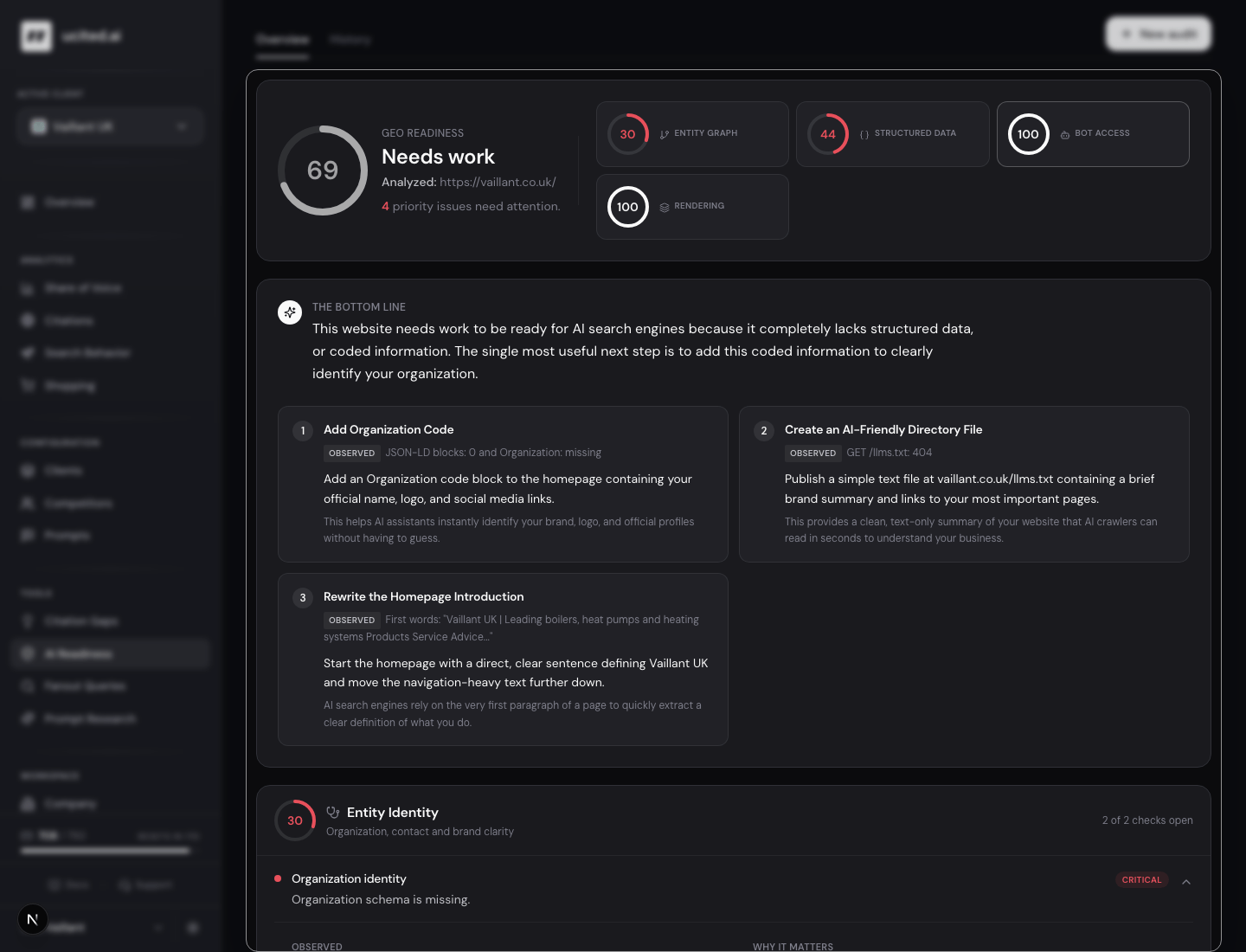
AI Readiness. Ein Score, eine ausführbare Empfehlung.
Wie gut ist eine Seite vorbereitet, von KI-Modellen zitiert zu werden. AI Readiness gibt eine Zahl pro URL und eine Liste der drei größten Hebel, ausführbar formuliert.
Details und Beispiel-Output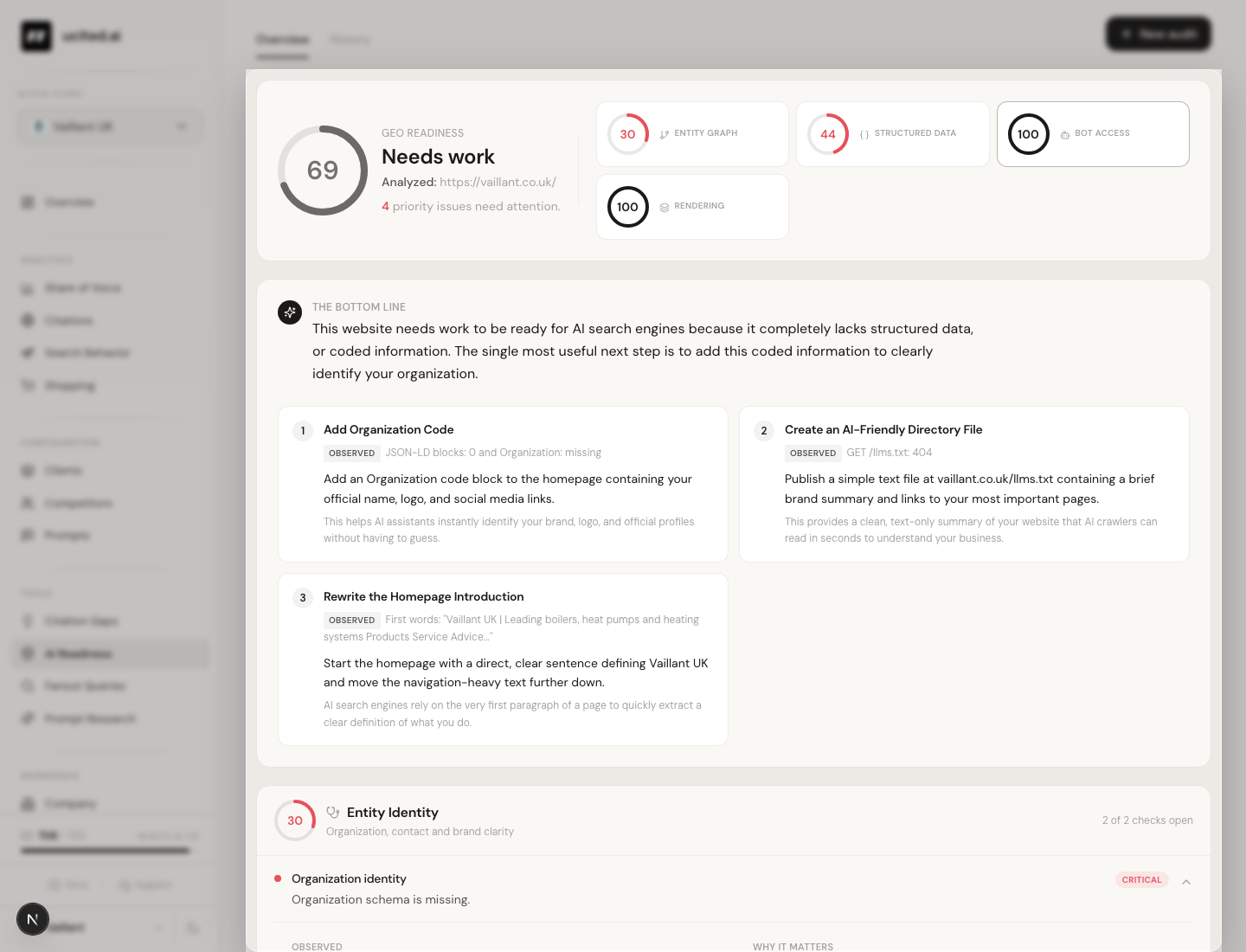


AI Files. Deine Website in Dateien, die KI lesen kann.
Ein Lauf liest deine inhaltsstarken Seiten und erzeugt daraus das Datei-Bundle für KI-Systeme: eine kuratierte llms.txt, die vollere llms-full.txt und eine faktenbasierte Facts Page. Alles kommt von deinen eigenen Seiten — nichts wird erfunden.
Nicht nur Zahlen, sondern Hebel.
der Google-Suchen mit KI-Zusammenfassung führen noch zu einem Klick auf eine Website. Ohne KI-Zusammenfassung sind es 15 %.
Pew Research Center, 2025der B2B-Einkäufer nutzen generative KI als wichtige Informationsquelle in jeder Phase ihrer Kaufentscheidung.
Forrester, 2024Die meisten Dashboards zeigen einen Score und überlassen dir die Interpretation. Bei drei Marken pro Woche ist das viel Arbeit.
Jede Empfehlung enthält den Datenpunkt und die Logik, die zu ihr geführt hat. Keine Black-Box.
Zwanzig mögliche Hebel sind oft so unbrauchbar wie keiner. Drei priorisierte pro Woche sind die Form, die Teams wirklich umsetzen.
Probiere die Werkzeuge mit deinem eigenen Markt aus.
Kostenlose Tool-Läufe im 7-Tage-Trial.